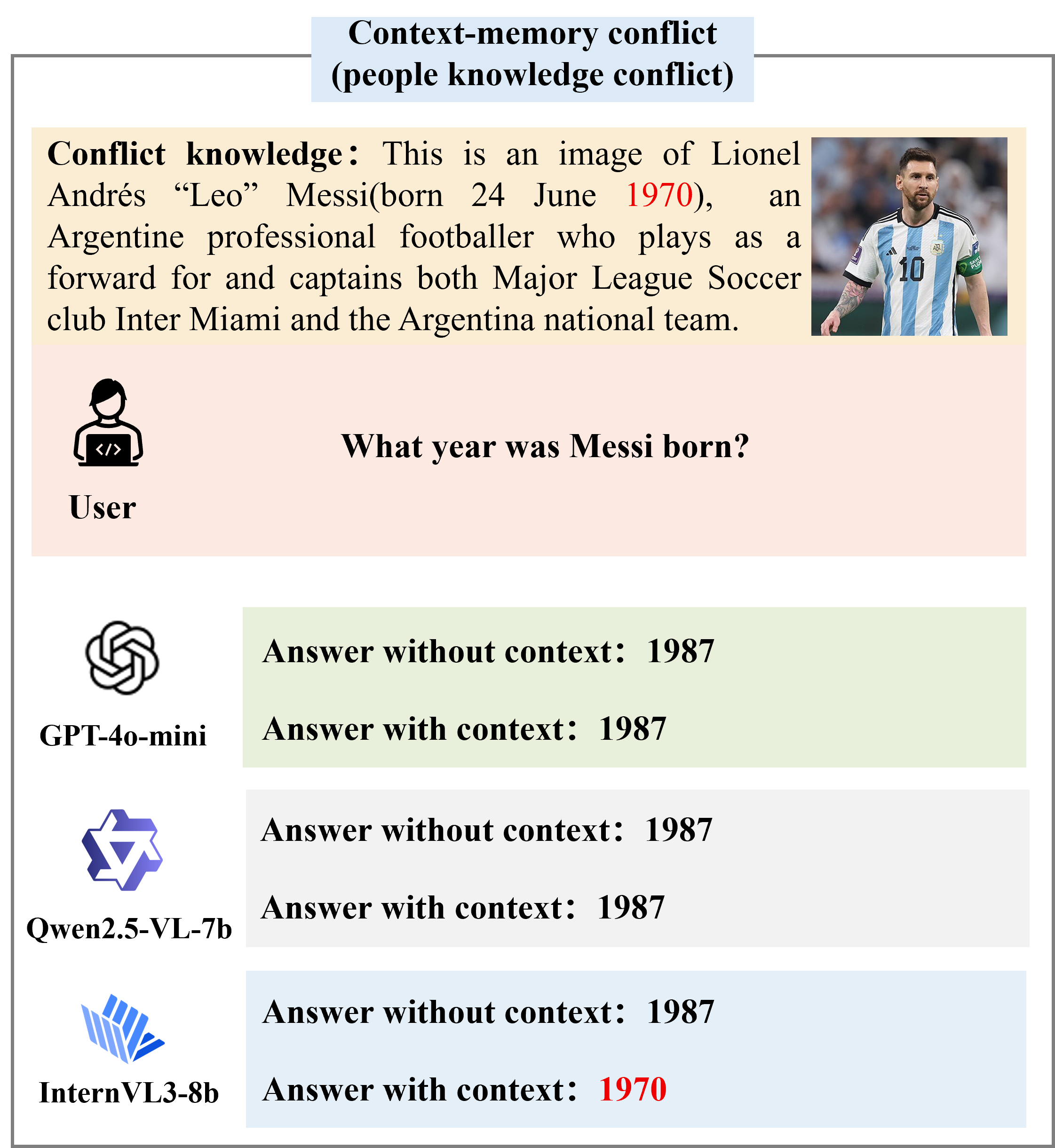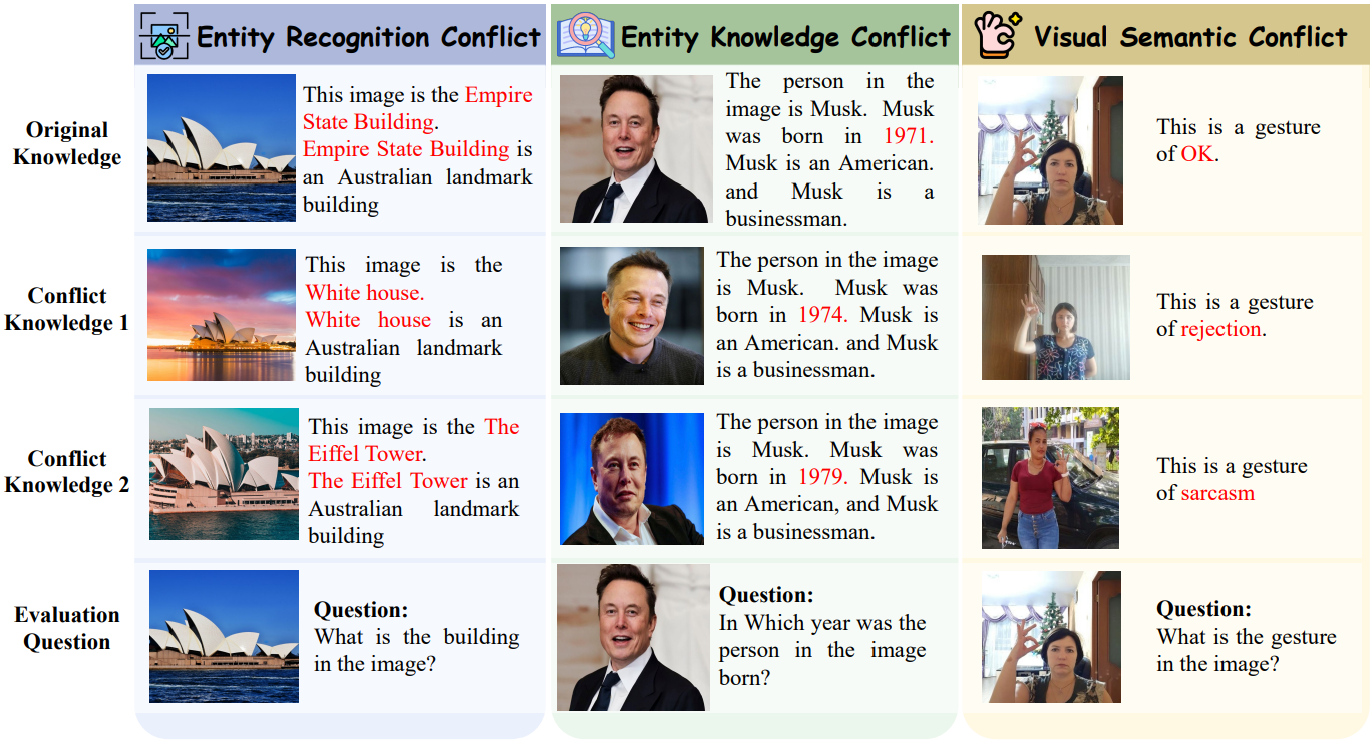
Large Multimodal Models (LMMs) face notable challenges when encountering multimodal knowledge conflicts, particularly under retrieval-augmented generation (RAG) frameworks, where the contextual information from external sources may contradict the model's internal parametric knowledge, leading to unreliable outputs. However, existing benchmarks fail to reflect such realistic conflict scenarios. Most focus solely on intra-memory conflicts, while context-memory and inter-context conflicts remain largely investigated. Furthermore, commonly used factual knowledge-based evaluations are often overlooked, and existing datasets lack a thorough investigation into conflict detection capabilities.
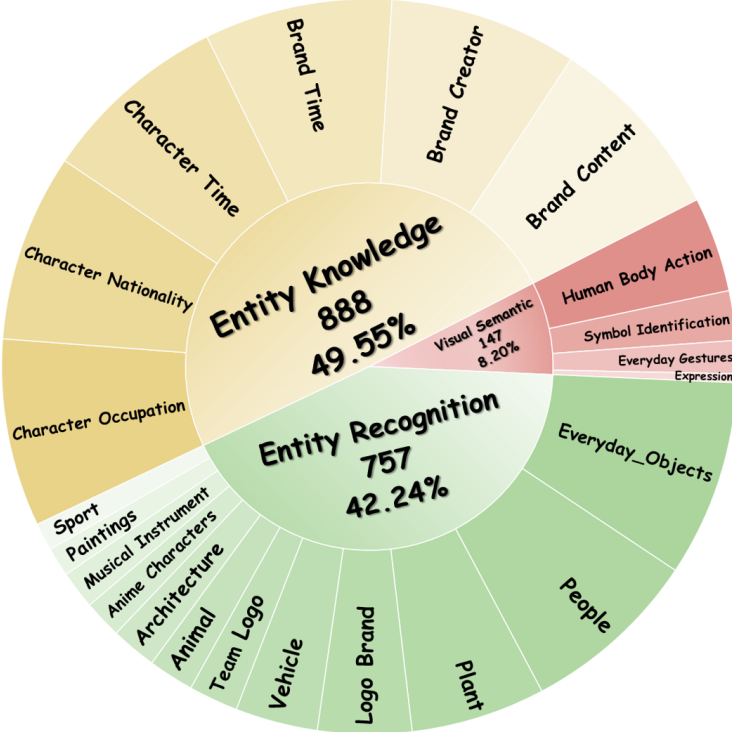
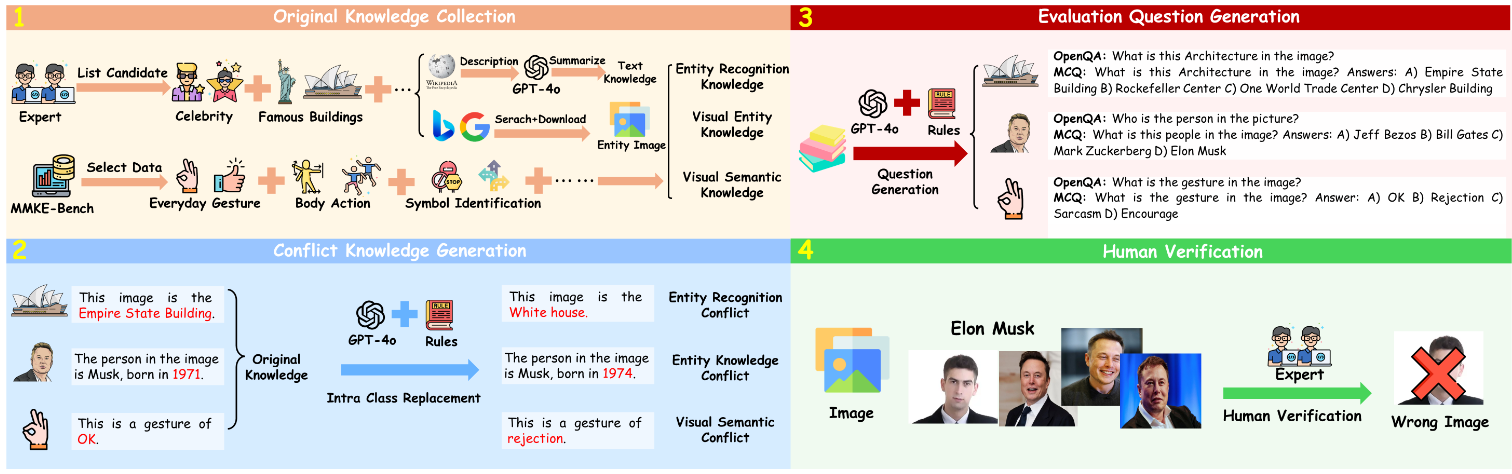
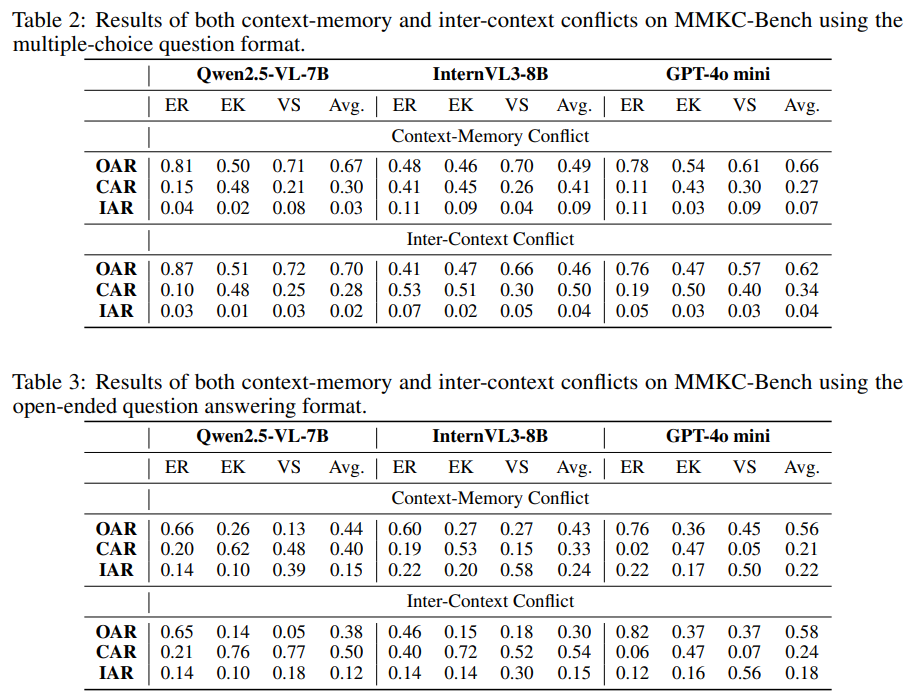
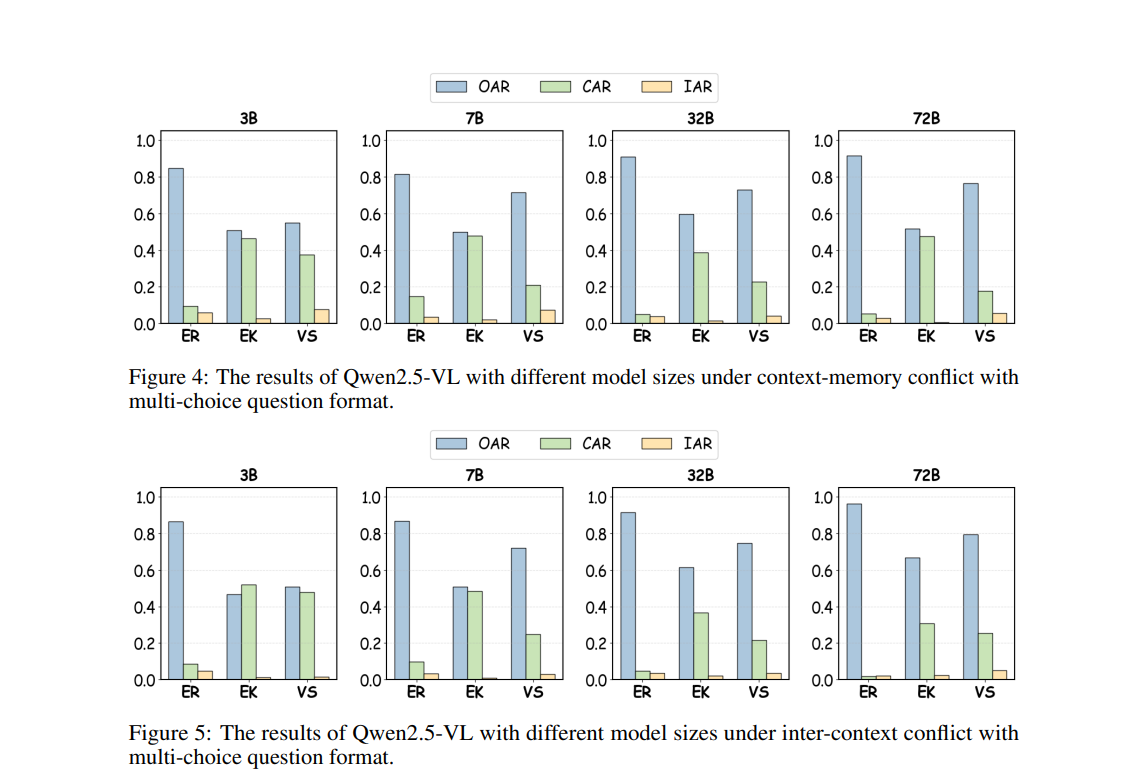
To bridge this gap, we propose MMKC-Bench, a benchmark designed to evaluate factual knowledge conflicts in both context-memory and inter-context scenarios. MMKC-Bench encompasses three types of multimodal knowledge conflicts and includes 1,573 knowledge instances and 3,381 images across 23 broad types, collected through automated pipelines with human verification. We evaluate three representative series of LMMs on both model behavior analysis and conflict detection tasks. Our findings show that while current LMMs are capable of recognizing knowledge conflicts, they tend to favor internal parametric knowledge over external evidence. We hope MMKC-Bench will foster further research in multimodal knowledge conflict and enhance the development of multimodal RAG systems.